Nvidia’s New Open-Source AI Model Beats GPT-4o On Benchmarks
Authored by Tristan Greene via CoinTelegraph.com,
Nvidia unceremoniously launched a new artificial intelligence model on Oct 15 that’s purported to outperform state-of-the-art AI systems including GPT-4o and Claude-3.

According to a post on the X.com social media platform from the Nvidia AI Developer account, the new model, dubbed Llama-3.1-Nemotron-70B-Instruct, “is a leading model” on lmarena.AI’s Chatbot Arena.

Nvidia AI announces the benchmarks score for Nemotron. Source: Nvidia AI
Nemotron
Llama-3.1-Nemotron-70B-Instruct is, essentially, a modified version of Meta’s open-source Llama-3.1-70B-Instruct.
The “Nemotron” portion of the model’s name encapsulates Nvidia’s contribution to the end result.
The Llama “herd” of AI models, as Meta refers to them, are meant to be used as open-source foundations for developers to build on.
In the case of Nemotron, Nvidia took up the challenge and developed a system designed to be more “helpful” than popular models such as OpenAI’s ChatGPT and Anthropic’s Claude-3.
Nvidia used specially curated datasets, advanced fine-tuning methods, and its own state-of-the-art AI hardware to turn Meta’s vanilla model into what might be the most “helpful” AI model on the planet.
An engineer’s post on X.com expressing excitement for Nemotron’s capabilities. Source: Shayan Taslim
“I asked it a few coding questions I usually ask to compare LLMs and got some of the best answers from this one. lol, holy shit.”
Benchmarking
When it comes to determining which AI model is “the best,” there’s no clear-cut methodology. Unlike, for example, measuring the ambient temperature with a mercury thermometer, there isn’t a single “truth” that exists when it comes to AI model performance.
Developers and researchers have to determine how well an AI model performs the same as humans are evaluated: through comparative testing.
AI benchmarking involves giving different AI models the same queries, tasks, questions, or problems and then comparing the usefulness of the results. Often, due to the subjectivity of what is and isn’t considered useful, human proctors are used to determine a machine’s performance through blind evaluations.
In Nemotron’s case, it appears that Nvidia is claiming the new model outperforms existing state-of-the-art models such as GPT-4o and Claude-3 by a fairly wide margin.
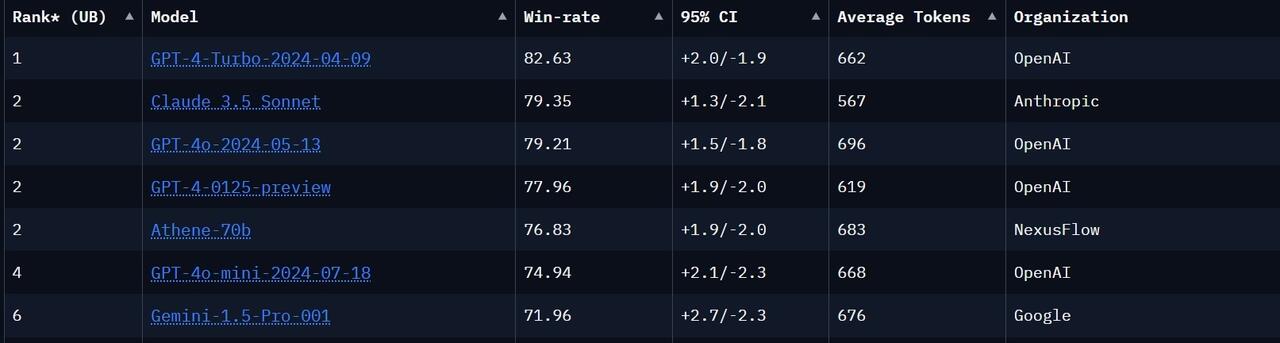
The top of the Chatbot Arena leaderboards. Source: LMArenea.AI
The image above depicts the ratings on the automated “Hard” test on the Chatbot Arena Leaderboards. While Nvidia’s Llama-3.1-Nemotron-70B-Instruct doesn’t appear to be listed anywhere on the boards, if the developer’s claim that it scored an 85 on this test is valid, it would be the de facto top model in this particular section.
What makes the achievement perhaps even more interesting is that Llama-3.1-70B is Meta’s middle-tier open-source AI model.
There’s a much larger version of Llama-3.1, the 405B version (where the number refers to how many billion parameters the model was tuned with).
By comparison, GPT-4o is estimated to have been developed with over one trillion parameters.
Tyler Durden
Thu, 10/17/2024 – 14:25
via ZeroHedge News https://ift.tt/XTJERUW Tyler Durden