Meet The Censored: The U.S. Right To Know Foundation
Authored by Matt Taibbi via TK News,
In July of 2020, a nonprofit watchdog group called the U.S. Right to Know Foundation — which describes its mission as exposing “corporate wrongdoing and government failures that threaten the integrity of our food system, our environment, and our health” — began filing requests for public documents “in an effort to discover what is known about the origins of the novel coronavirus SARS-CoV-2,” which “causes the disease Covid-19.”

Later in the year, the Foundation began publishing the results of those document requests. These included reports of unsafe conditions at biolabs in Fort Collins, Colorado, as well as emails connected with the EcoHealth Alliance, an American non-profit that has been supported in part by taxpayer-funded grants, and has collaborated with the Wuhan Institute of Virology.
Those emails were not flattering to the EcoHealth Alliance. They showed that its leadership had a role in helping organize a letter in the prominent medical journal, The Lancet, denouncing as “conspiracy theory” the idea that Covid-19 might have had laboratory origins, but appeared reluctant to have its own involvement made public. In one email, EcoAlliance president Peter Daszak appeared to suggest distancing itself from the Lancet statement.
“We’ll then put it out in a way that doesn’t link it back to our collaboration so we maximize an independent voice,” the EcoHealth president wrote.
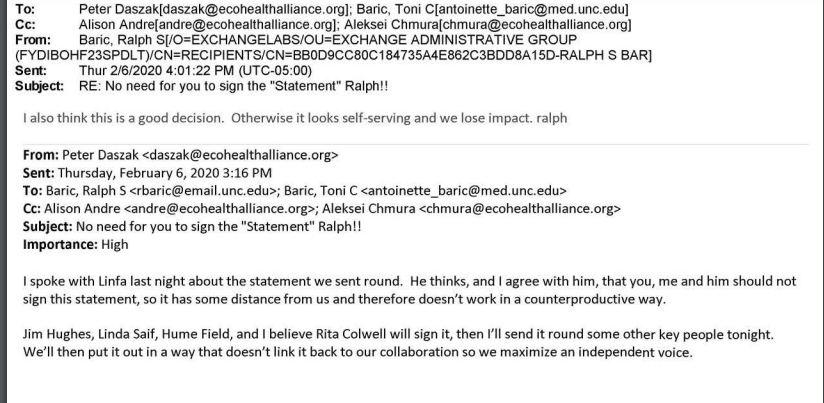
Despite the correspondence, Daszak did ultimately sign the letter publicly, and the emails are not proof of anything, other than that EcoAlliance had some P.R. concerns about seeming too eager to denounce theories of laboratory origin for Covid-19. Still, it’s clearly in the public interest.
USRTK, whose reporting is mostly based on public document searches, is an organization that inspires strong opinions. They inhabit a corner of the media universe focusing on who pays for what kind of research, and to what result, around topics like food additives and Genetically Modified Organisms. The material can get very personal, and thanks to headlines like “The misleading and deceitful ways of Dr. Kevin Folta,” they’re not generally in the friend-making business.
Moreover, agencies like USRTK are particularly vulnerable in the age of algorithmic moderation, as computers don’t easily distinguish between conspiracy theory and legitimate reporting that runs counter to present accepted narratives. Any organization that swims in those waters and isn’t attached to a big name now has to keep looking over its shoulder. If such an organization does end up suspended, deleted, or de-ranked, as USRTK later would be, it has to wonder: was it something we wrote?
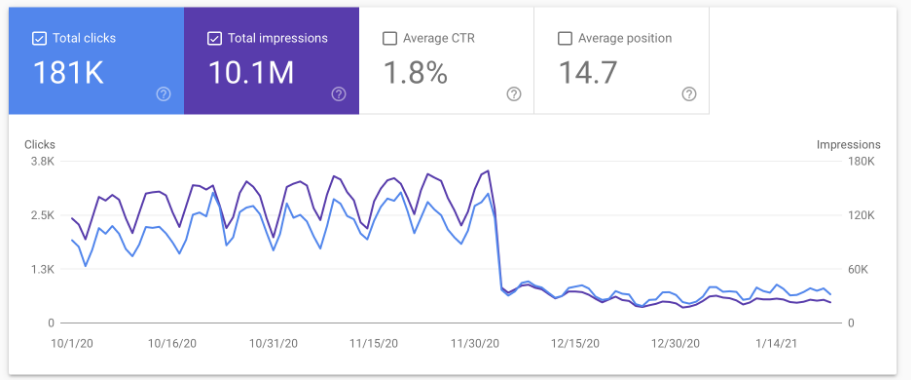
As a nonprofit, USRTK isn’t terribly click-conscious, and director Gary Ruskin wasn’t aware initially that its traffic went off a cliff in December, 2020, dropping nearly 60% overnight:
The World Socialist Web Site had to conduct its own analysis to discover a similar drop in traffic after Google’s “Project Owl” update in early 2017. Other sites, like the Chris Hedges-led TruthDig, had to perform similar self-analysis to find similar drops.
In other words, when an individual or outlet sees a significant drop or a ban, they’re rarely told what’s happening. An overnight, ongoing, 60% drop in traffic is not likely an organic phenomenon, but what is it? Ruskin only had a few data points to work with.
“On December 2nd, things were good,” he says. “On December 4th, the bottom fell out.”
Did anything happen in that time frame? As it turns out, yes. On December 3rd, Google announced a “core algorithm update.” Google changes its search algorithm daily, but makes what it calls “significant, broad changes” several times a year. The company has obviously dealt with the problem of people negatively impacted by these changes, having posted notices offering public advice to those affected.
“Some sites may note drops,” the company wrote, in 2019. “We know those with sites that experience drops will be looking for a fix, and we want to ensure they don’t try to fix the wrong things. Moreover, there might not be anything to fix at all.”
Translation: you may not be doing anything wrong. You may just be screwed. However, just in case you did want to try to unscrew yourself, the company offers the following Platonic advice: ask questions. Self-interrogate! A sample (emphasis mine):
Does the content provide original information, reporting, research or analysis?
If the content draws on other sources, does it avoid simply copying or rewriting those sources and instead provide substantial additional value and originality?
Does the headline and/or page title avoid being exaggerating or shocking in nature?
Would you expect to see this content in or referenced by a printed magazine, encyclopedia or book?
Is this content written by an expert or enthusiast who demonstrably knows the topic well?
Does the content have an excessive amount of ads that distract from or interfere with the main content?
Does the content seem to be serving the genuine interests of visitors to the site or does it seem to exist solely by someone attempting to guess what might rank well in search engines?
U.S. Right to Know is basically ad-free. It doesn’t aggregate, but instead publishes original reporting based mainly on public documents. It’s the opposite of a click-chasing SEO-oriented site that is “attempting to guess what might rank well.” It doesn’t have shocking or sensational headlines — in fact, it barely had an engagement strategy. Its work is referenced by peer-reviewed medical journals and established outlets like the New York Times.
Once the December drop was detected, Ruskin reached out to more computer-savvy folks to ask how they could fix whatever they were doing wrong. Those experts in SEO optimization could only offer a little advice.
“We’re talking to some search engine people who offered suggestions,” Ruskin says. “They tell us things like, ‘Oh, that’ll affect a tenth of a percent of your problem, but we don’t understand the other 99.9% of it.’”
A consistent detail in these stories is that the affected outlet doesn’t know whom to call to ask for help. Nearly everyone ends up going through their contact lists in search of someone who might know someone at a company like Google.
Ruskin did get a name to contact at the firm, and wrote a note that detailed his credentials and showed the dramatic drop in traffic. The Google staffer wrote back with a standard-issue reply:
Our December 2020 core update, like any core update, does not involve particular sites. We explain a bit more about core updates in our post about them: “There’s nothing in a core update that targets specific pages or sites…”
The staffer went on to say that she was happy to pass complaints on, but that not only would nothing be done right away, nothing could be done for any individual site, even if they wanted to try. Note the Kafka-style “nor could we” phrase here:
I’ve passed along your feedback to our teams for general review. This will not result in any immediate change, nor could we make such a change, given that core updates don’t involve the ranking of particular sites. But our teams may use this feedback to understand how to make general improvements in our ranking systems overall.
The Freedom of the Press Foundation, which had a similar issue with its own database of Donald Trump tweets, picked up on USRTK’s story in a piece called, “When Algorithms Come for Journalists” that also highlighted stories profiled in this space, like the one involving Jordan Chariton’s Status Coup. In describing its own problems with its Trump tweets data, the site wrote:
Still, we were lucky. Some of our colleagues know employees at Google… After many people made private inquiries on our behalf, the document was restored without explanation a day after we discovered it was down. Obviously, that course of action is not available to most. We still have no idea why the Trump tweet database was taken down.
Not long ago, outlets like USRTK mainly had to worry about PR campaigns. The Freedom of the Press Foundation noted, for instance, that the organization had been one subject of a much-publicized effort by Monsanto to discredit its work, setting up an online “intelligence center” that produced weekly reports on the organization’s activity.
Or: has the site crossed an unknown line with its Covid-19 reports, which include lines like, “To date, there is not sufficient evidence to definitively reject either zoonotic origin or lab-origin hypotheses”? Language like that seemed to be okay when The Telegraph ran headlines like “Scientists to examine possibility Covid leaked from lab as part of investigation into virus origins.” But is it less okay when a different site says something similar? Is there something in the algorithm that triggers such reactions? Who knows? Companies like Google only speak in riddle-like generalities when queried about things like this, sounding like Confucian sages, or Alan Greenspan.
I spoke to Ruskin about his organization’s experience:
TK: What happened?
Ruskin: We don’t know. There was a big core update in December of 2020 that the timing corresponds exactly with this, but that doesn’t prove that it was it.
TK: Would a core update be responsible for that big of a drop in traffic?
Ruskin: You’re asking the wrong guy. I mean, there are a couple of articles that explain in very opaque language what it did, but to my understanding, it doesn’t say anything that is pertinent to us. There was nothing that jumped out at me. That’s part of what’s Kafkaesque about this whole process: there have been no explanations, no one to appeal to, to talk with.
TK: Will this affect your funding, your ability to keep working?
Ruskin: Certainly it’s easy to imagine how it could, but we do our work so that it gets read and so that the world understands what we’re trying to explain about public health. And now so many fewer people read our stuff, can find our stuff.
Our organization, we spent six years of blood, sweat, and tears to build this website, which up until December, lots of people looked at. And now it’s not so many people look at it and nobody told us why. That’s one of the concerning things about the whole story. In some ways, Google has the power to decide what we all read, and that’s more power than one corporation should hold.
TK: Is this censorship, or a glitch? Has this been a learning experience?
Ruskin: I really strongly believe in the First Amendment and have been concerned for probably during that entire period about when the censors come for someone, they could easily come for you tomorrow. So that, I think, is the lesson of history. But I can’t say that this is censorship, because I don’t have the faintest idea. That’s another part of what’s so frustrating.
It’s so hard to believe that this has happened, and there’s no reason for it that we can uncover. It happened all of a sudden, we’re wondering if it will go away all of a sudden. So maybe that’s wishful thinking. We don’t know what to do. We’re talking to some search engine people… We’re doing a little of that to try to see if there’s anything sensible to be understood and done. We’re making a few better URLs than the ones we had, which were crummy. But nobody thinks that that’s the reason for this.
TK: Is that the hardest thing about these situations? That there’s no procedure for fixing something like this?
Ruskin: Absolutely. It’s straight out of Kafka. What door do I knock on?
Tyler Durden
Thu, 04/08/2021 – 21:00
via ZeroHedge News https://ift.tt/2Oz3yN9 Tyler Durden